Os repositórios de código-fonte dos sistemas que uma empresa desenvolve são o “coração” da engenharia de software.
Empresas maduras na capability de engenharia de software têm repositórios “saudáveis”, ou seja, que facilitam a implementação ágil de mudanças (implementações e correções) nos sistemas – com baixo development lead-time e alta frequência de deploys – e facilitam a colaboração. Por outro lado, repositórios “doentes” dificultam a resolução de problemas do dia-a-dia, sendo, inclusive, difíceis de monitorar, impedindo a adoção de práticas reconhecidamente positivas, como continuous integration e continuous deployment.
Continuous Integration (CI), Continuous Delivery e Continuous Deployment (CD)
Continouous Integration (CI) é uma prática de engenharia onde código é integrado em um repositório compartilhado com maior frequência possível – de preferência várias vezes ao dia. Cada integração geralmente é verificada por compilação e testes automatizados.
Continuous Delivery é uma extensão da Continuous Integration, pois implanta automaticamente todas as alterações de código em um ambiente de teste e/ou produção após o estágio de compilação.
Finalmente, Continuous Deployment (CD) vai um passo além da Continuous Delivery. Com essa prática, toda mudança que passa por todas as etapas do seu pipeline de produção é liberada para seus clientes. Não há intervenção humana e apenas um teste com falha impedirá que uma nova alteração seja implantada na produção.
Modernamente, a maioria das empresas utiliza alguma implementação de git como base tecnológica para controlar seus repositórios. Uma das abordagens mais efetivas para utilizar git do jeito certo é o git flow.
Git
Git é um sistema de controle de versões distribuído, usado principalmente no desenvolvimento de software, mas pode ser usado para registrar o histórico de edições de qualquer tipo de arquivo (Exemplo: alguns livros digitais são disponibilizados no GitHub e escrito aos poucos publicamente).
O Git foi inicialmente projetado e desenvolvido por Linus Torvalds para o desenvolvimento do kernel do Linux, mas foi adotado por muitos outros projetos.
O que é e quando usar “Git flow”
O Git flow é um “modelo opinativo” de trabalho para equipes de engenharia de software que utilizam Git. Ele foi idealizado por Vincent Driessen em 2010 e se destaca pela fluidez que adiciona ao processo para desenvolvimento de novas funcionalidades, correções de bugs e lançamento de versões.
 | A successful Git branching model Artigo original, escrito por Vincent Drissen em 2010, onde ele propõe o git flow. Trata-s de uma excelente referência, detalhada e ilustrada, do modelo. |
O modelo proposto por Drissen, segundo o próprio autor, é ideal para projetos que utilizam versionamento semântico ou quando times precisam suportar várias versões, em produção, simultaneamente.
Definição: Semantic versioning
Semantic versioning é uma estratégia para determinação de versões, utilizando números, em um esquema, MAJOR.MINOR.PATCH, onde deve-se incrementar o major quando as mudanças implementadas geram incompatibilidade com versões anteriores, minor quando forem adicionadas funcionalidades mantendo a compatibilidade e, finalmente, patch quando há apenas correção de falhas.
Como funciona o “Git Flow“
O Git Flow trabalha com duas branches principais, a Develop e a Main (antigamente Master), que são mantidas no repositório indefinidamente. Além delas recomenda-se manter uma branch para cada release que se deseja disponibilizar.
A partir das branches principais, podem ser criadas outros dois tipos de branches: Feature e Hotfix, temporárias e mantidas até serem mescaladas com as branches principais.
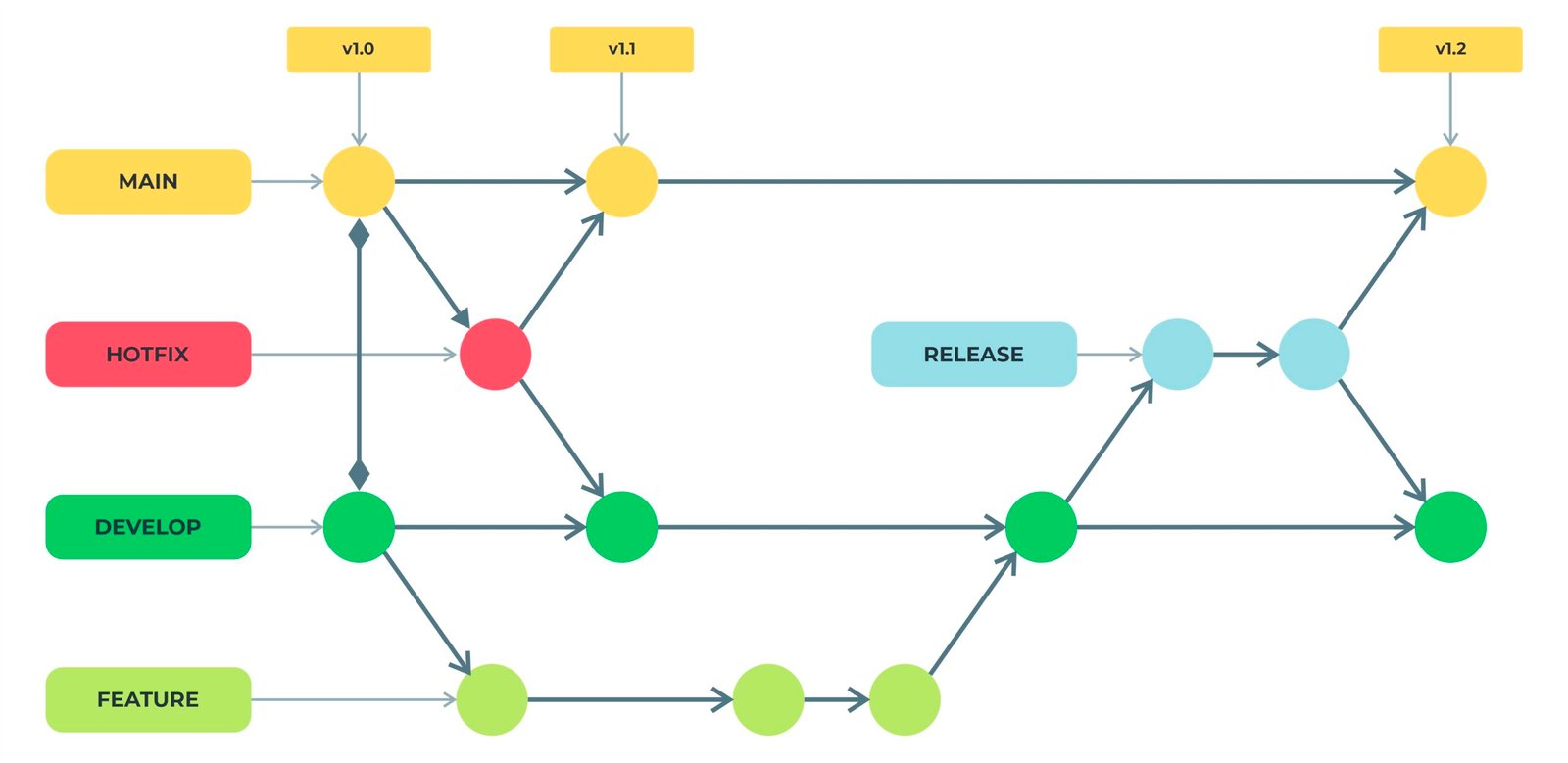
A branch Main armazena o histórico oficial de lançamentos, enquanto a branch Develop é base para integração.
Toda vez que uma nova feature for desenvolvida, uma branch específica deve ser iniciada a partir da branch Develop. Idealmente, esta branch deverá ser nomeada conforme padrão fixo (ex: feature/<nro. do documento de solicitação). Ela deverá existir até que a implementação esteja concluída quando, então, deverá ser mesclada com a branch develop.
 | O número de branches Feature abertas corresponde ao número de funcionalidades que estão sendo desenvolvidas simultaneamente. Em times de engenharia que adotam kanban, elas ajudam a controlar o Work in Progress. |
Sempre que uma correção imediata, em produção, for necessária, uma branch hotfix deve ser iniciada, a partir da Main. Idealmente, essa branch deverá ser nomeada conforme padrão fixo (ex: hotfix/<nro. do documento de solicitação>). Ela deverá existir até que a correção esteja implementada e pronta para ser integrada tanto na branch Main quanto Develop. Além disso, toda vez que for realizado um merge com a Main, uma tag indicativa de versão deverá ser indicada.
| O número de branches Hotfix abertas corresponde ao número de erros em produção que estão sendo corrigidos simultaneamente. A comparação entre a quantidade de branches Feature e Hotfix serve como um “retrato” do momento do time. |
Métricas! Métricas!
A adoção do git flow oferece excelentes alternativas para coleta duas métricas fundamentais: development lead-time e frequência de deploy.
 | Métricas importantes para a engenharia de software Development lead-time e frequência de deploy são parte de um conjunto de quatro métricas essenciais para gestão de times ágeis. Quer saber mais sobre? Leia o tópico em que as apresentamos. Acessar tópico |
Development lead-time pode ser “simplificado”, em projetos ativos, para o intervalo de tempo entre tags indicando versões que introduzem features. De forma análoga, a frequência de deploy pode ser medida a partir da quantidade de tags indicando versões que introduzem features em um determinado intervalo de tempo (por exemplo, em um mês).
Uma restrição importante
Para pensar…
Mesmo com algumas limitações perceptíveis, entendo que o modelo ajuda organizações de engenharia a por a “casa em ordem”, habilitando trabalho simultâneo, colaboração e suporte para correções rápidas.


Eu gosto de usar um git-flow, aonde trabalho por exemplo temos 3 branchs principais: Master, Development e Stagin.
Como trabalhamos com uma aplicação monolítica, ao qual todos os clientes utiliza o mesmo repositório GIT.
Toda branch de desenvolvimento sai da Development, após a conclusão sobe para Staging que no final quando QA válida em um ambiente comunitário, a branch é feita o merge na Development e posterior na Master. Caminho feliz rs…
Temos alguns problemas referente a este processo, quando um bug não mapeado sobe, sobe para todos. Posso dizer que a aplicação é “rolling release” rs.
A grande barreira que temos hoje é como criar um git-flow que nos atenda e não gere entregas de bugs no pool de clientes.
Meu resumo, acredito que o git-flow ajuda e muito, mas tendo uma pitada de ajustes de acordo com cada empresa ou projeto.
Outro aspecto interessante é que Gitflow irá funcionar melhor quando o time trabalhar em um modelo de sprints, entregando batches de features ao final de cada iteração.